Most growth teams manually click through a competitor's website, taking fragmented screenshots of pricing pages and skimming blog posts to guess their content strategy. Meanwhile, AI engines like Perplexity, Gemini, and ChatGPT are programmatically reading, structuring, and citing those exact same pages in milliseconds.
If you want to understand why a competitor consistently wins AI Overviews or dominates feature comparisons in LLM prompts, manual clicking won't cut it. You have to look at their web presence the way machines do.
Scraping allows you to map a competitor's entire content footprint, extract their exact H2 architectures, pull pricing matrices, and identify the external sources they cite. This structured data is the foundation of modern visibility monitoring. Once you extract it, you can pinpoint the exact semantic gaps in your own content and turn those missing mentions into published work.
Here is a practical breakdown of how to scrape a website for competitor insights, the tools that make it accessible for both technical and non-technical teams, and the exact steps to turn raw HTML into an execution roadmap.
Why Scraping Matters for AI-Search Visibility in 2026
Web scraping is no longer just about monitoring competitor pricing. In the era of AI search, scraping is how you reverse-engineer visibility.
AI assistants synthesize answers based on how well a brand structures its information. When BeVisible helps teams monitor how AI assistants answer buyer questions, a recurring pattern emerges: the brands that get recommended are the ones with the most consistently structured, easily readable web data.
By scraping your competitors' highest-visibility pages, you uncover:
- Entity Density: Which specific industry terms, brand names, and integrations they mention.
- Citation Networks: Which external domains they link out to (and which ones link back to them), mapping their authority footprint.
- Information Architecture: How they nest their H2s, H3s, and FAQ sections to feed LLM intent engines.
- Hidden Schema: The JSON-LD structured data they use to explicitly tell search engines what their product does.
If a competitor is winning a critical buyer prompt in ChatGPT, scraping their cited source page gives you the exact blueprint of what your own content is missing.
5 Simple Tools to Scrape Competitor Sites
Choosing the right web scraping tool depends entirely on your team's technical resources and the complexity of the target website. Here are the five most effective tools for extracting competitor insights, ranging from zero-code visual builders to robust developer frameworks.
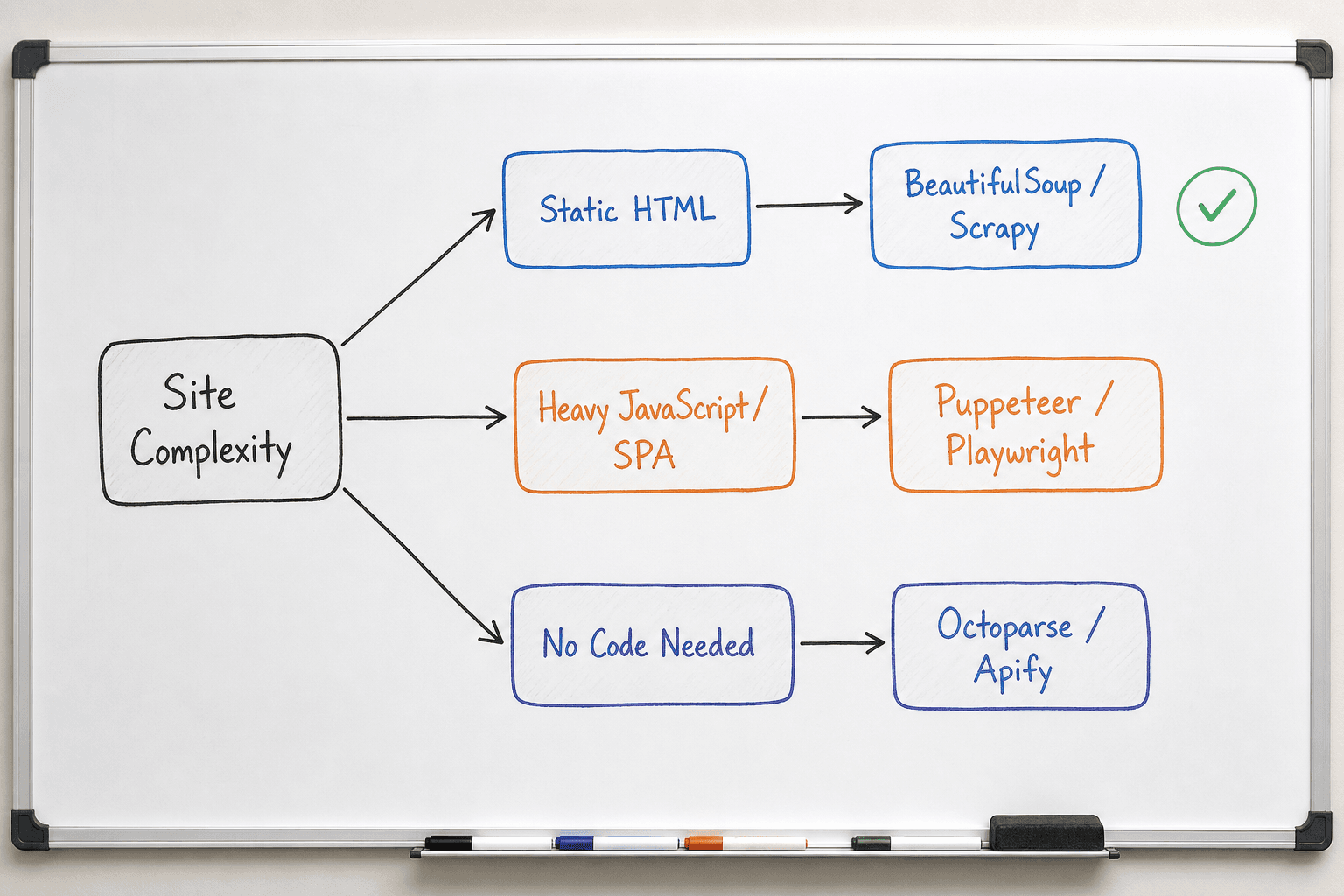
1. Octoparse (Best for Non-Technical Teams)
Octoparse is a visual, no-code scraping tool designed for marketers and analysts. Instead of writing code, you navigate to a competitor's URL within their built-in browser and point-and-click on the elements you want to extract—like blog titles, publish dates, author names, or pricing tiers.
Where it excels:
- Pagination: It automatically handles "Next Page" buttons and infinite scrolling.
- Exporting: You can send scraped data directly to Excel, Google Sheets, or a database via API.
- Cloud Extraction: You can schedule the scraper to run weekly on their cloud servers, allowing you to track a competitor's blog output over time without leaving your computer on.
Tradeoffs: The visual interface can feel clunky on highly complex, animated websites, and heavy scraping tasks require a paid subscription.
2. Apify (Best for Ready-Made Scalability)
Apify is a cloud scraping platform that hosts "Actors"—pre-built scraping programs designed for specific use cases. If you want to scrape a competitor's entire sitemap or pull data from specific social platforms, chances are an Apify Actor already exists for it.
Where it excels:
- Speed to value: You don't have to build the scraper from scratch. You simply input a competitor's URL into a pre-built Actor and wait for the JSON/CSV output.
- Built-in Proxies: Apify manages proxy rotation automatically, drastically reducing the chances of your scrape being blocked by basic bot protection.
- Integration: It integrates beautifully with webhooks, Zapier, and Make, allowing you to feed competitor data directly into your CRM or content pipeline.
Tradeoffs: It operates on a consumption-based pricing model. Running heavy, compute-intensive browser automation can eat through credits quickly.
3. Playwright / Puppeteer (Best for Heavy JavaScript & SPAs)
If your competitor relies heavily on JavaScript frameworks like React, Vue, or Angular, traditional scrapers will only see a blank page. Playwright (maintained by Microsoft) and Puppeteer (maintained by Google) are "headless browsers." They actually open a hidden browser window, execute the JavaScript, wait for the page to render, and then extract the data.
Where it excels:
- Dynamic Content: Unbeatable for scraping Single-Page Applications (SPAs) where content loads dynamically upon scrolling or clicking.
- User Emulation: You can program them to fill out forms, bypass simple pop-ups, and mimic human scrolling behavior.
Tradeoffs: They are code-heavy (Node.js/Python) and highly resource-intensive. Running 1,000 headless browser instances requires significant server power. If you are analyzing how search engines view these dynamic pages, check out our guide on Implementing SEO in Single Page Applications (3 Ways).
4. Scrapy (Best for Massive Crawl Volume)
Scrapy is a powerful, open-source Python framework designed for speed. Unlike headless browsers that render every visual element, Scrapy sends raw HTTP requests and parses the response asynchronously.
Where it excels:
- Scale: If you need to scrape a competitor's 10,000-page e-commerce catalog or their entire documentation hub, Scrapy can do it in minutes, not hours.
- Custom Pipelines: You can write custom logic to clean the data (e.g., stripping out HTML tags) before saving it to your database.
Tradeoffs: Scrapy does not execute JavaScript out of the box. If the data is hidden behind an API call or client-side rendering, Scrapy will miss it unless paired with a middleware tool like Splash.
5. BeautifulSoup (Best for Quick Python Parsing)
BeautifulSoup is a Python library dedicated to parsing HTML and XML documents. It is not a crawler (you use the requests library to fetch the page), but it is the easiest way for a growth engineer to extract specific data hooks from static HTML.
Where it excels:
- Simplicity: It provides intuitive ways to navigate the DOM. You can find all elements with the class
.pricing-table-tierin a single line of code. - Prototyping: Ideal for quickly checking if a competitor's schema markup has changed or extracting all the H2 tags from their latest blog post.
Tradeoffs: Like Scrapy, it cannot handle dynamically rendered JavaScript content on its own.
How to Scrape Competitor Sites for Visibility Gaps: A Step-by-Step System
Knowing the tools is only half the battle. To turn raw data into actionable content briefs, reviews, and scheduling workflows, you need a systematic approach to extraction.
Step 1: Map the Target URLs (The Discovery Phase)
You rarely want to scrape an entire website aimlessly. Start by identifying the highest-leverage URLs.
Look for the competitor's sitemap_index.xml (usually found at competitor.com/sitemap.xml). This file reveals their exact content architecture. Filter the sitemap to extract URLs for their blog, their feature pages, and their integration directories.
Alternatively, if you are monitoring AI citations and know that ChatGPT consistently links to five specific pages on a competitor's site, make those five URLs your target list.
Step 2: Inspect the DOM & Identify Data Hooks
Before writing code or clicking through a visual tool, right-click on the competitor's webpage and select Inspect. This opens the developer tools, allowing you to see the underlying HTML.
 Look for repeating patterns. Developers build sites using classes and IDs to style elements. You will use these exact classes as your "hooks" for scraping.
Look for repeating patterns. Developers build sites using classes and IDs to style elements. You will use these exact classes as your "hooks" for scraping.
For example, if you want to scrape a competitor's feature comparison table, you might find that every feature is wrapped in <div class="feature-comparison-row">. You will tell your scraper (whether using Octoparse or BeautifulSoup) to target that specific class.
Key elements to target for competitor insights:
<title>and<meta name="description">to track their positioning.<h1>,<h2>, and<h3>tags to steal their content outlines.<script type="application/ld+json">to extract their structured schema data (which often contains pristine, machine-readable Q&As or product specs).<a href="...">tags within the body content to map their internal linking strategy.
Step 3: Handle Dynamic Content and SPAs
Modern web architecture is a major hurdle for simple scrapers. If a competitor uses a Single-Page Application (SPA), the initial HTML response might just be an empty <div> with a link to a JavaScript bundle.
If you inspect the page source and don't see the text that is visible on the screen, you are dealing with client-side rendering.
To bypass this, you must use a headless browser (Puppeteer/Playwright) or route your scraping requests through a rendering service. This ensures the JavaScript executes and the content populates before extraction. For a deeper understanding of how these architectures impact visibility, review Single-Page Application SEO: What Works in 2026?.
Step 4: Clean and Structure the Data
Raw scraped data is usually messy. It contains line breaks, HTML tags, and trailing spaces. Before analyzing the data, pass it through a cleaning pipeline.
- Strip HTML tags: Keep only the raw text.
- Standardize formats: Convert all dates to a unified format (e.g., YYYY-MM-DD).
- Export to JSON or CSV: Move the data into a structured format that can be easily filtered in a spreadsheet or ingested by a large language model for analysis.
Step 5: Turn Data into Published Work
This is where visibility monitoring comes full circle. Look at the structured data you just extracted from a competitor's highest-performing pages.
- Did they structure their pricing page as a dense FAQ that AI engines love?
- Did they mention a specific set of niche integrations that your feature pages miss?
- Did they define industry jargon explicitly in their H2s?
Use these insights to brief your own content team. When you know exactly what architecture the AI engines are rewarding, you can map out better assets. (For a practical guide on deploying these structural insights, read How to Build an SEO Landing Page (7-Step Guide)).
Best Practices: Scraping Without Getting Blocked
Websites protect their data. If a competitor notices a sudden spike in traffic coming from a single server requesting 500 pages a second, their Web Application Firewall (WAF) like Cloudflare will block your IP address permanently.
To scrape reliably, you must act like a human user.
1. Respect the robots.txt File
Always check competitor.com/robots.txt before scraping. This file tells bots which directories they are allowed to crawl and which they should avoid. While strictly adhering to it is voluntary, blatantly ignoring directives is a quick way to get your IP flagged.
2. Implement Rate Limiting
Do not hit a server with hundreds of concurrent requests. Add random delays between your page requests (e.g., wait between 2.5 and 5 seconds before loading the next URL). This mimics human browsing speed and keeps the competitor's server from crashing.
3. Rotate User-Agents and Headers
Every time you visit a website, your browser sends a "User-Agent" string identifying itself (e.g., "Chrome on macOS"). Default scraping libraries often send obvious bot strings (like python-requests/2.31). Always configure your scraper to send a real, up-to-date User-Agent string.
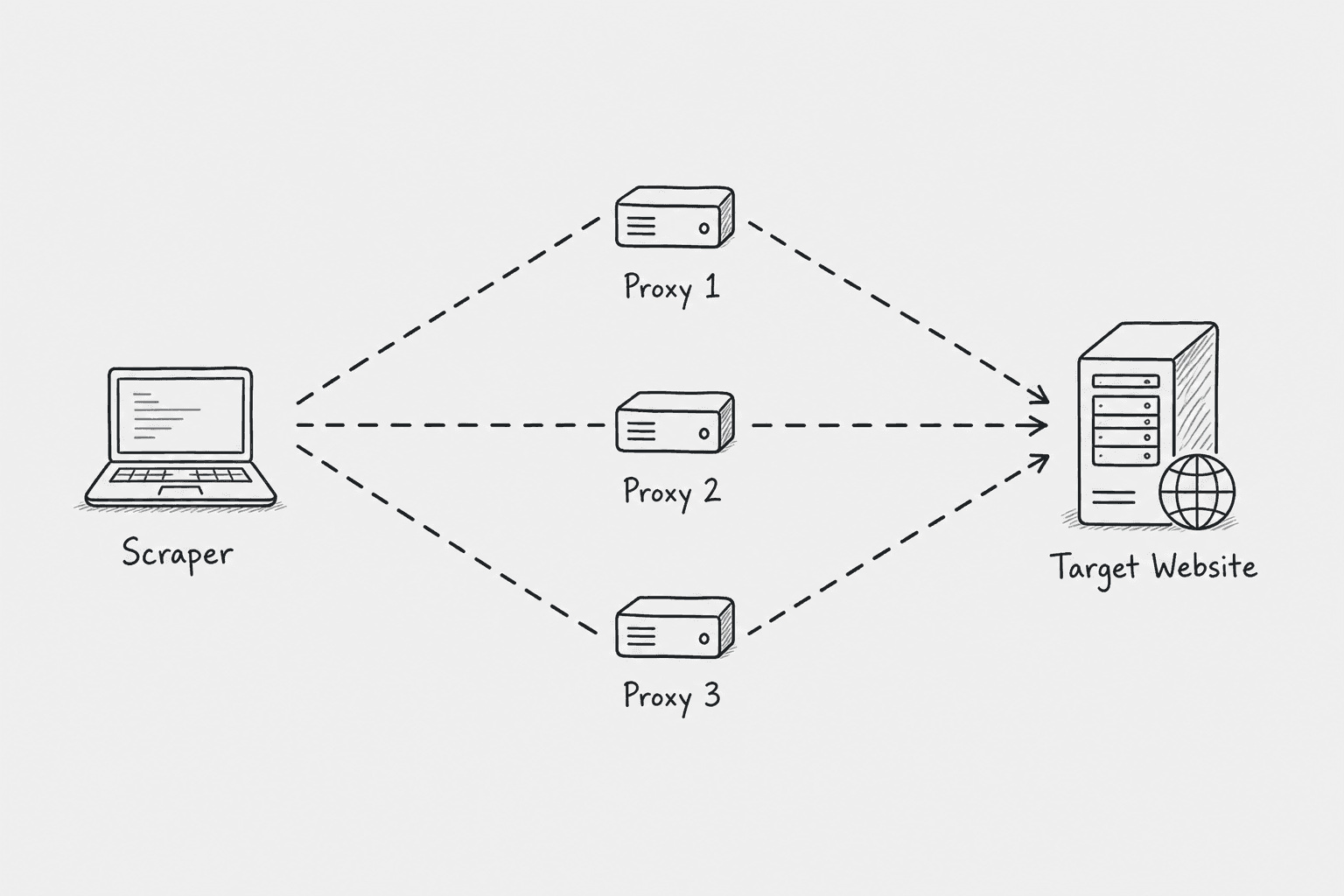
4. Use Proxy Networks
If you are scraping at scale, a single IP address will inevitably hit a block. Proxy networks route your requests through hundreds of different IP addresses (often residential IPs), making your scraping activity look like organic traffic coming from regular users across the country.
Frequently Asked Questions (FAQ)
Is web scraping legal for competitor analysis?
In most jurisdictions, scraping publicly available web data is perfectly legal. The U.S. Ninth Circuit Court of Appeals (in the highly cited hiQ Labs v. LinkedIn case) reinforced that accessing public data does not violate the Computer Fraud and Abuse Act (CFAA).
However, scraping behind a login wall, copying copyrighted content verbatim for publication, or extracting Personally Identifiable Information (PII) crosses legal boundaries. Stick to analyzing public content architectures, pricing, and entity mentions.
How do I scrape a website that requires a login?
Scraping authenticated data requires passing session cookies or authentication tokens with your HTTP requests. Headless browsers like Puppeteer can be programmed to physically type credentials into a login form, capture the resulting session cookie, and pass that cookie along with subsequent requests. Just ensure you are not violating the platform's terms of service by automating authenticated accounts.
Can I use ChatGPT to scrape websites?
Not directly. While ChatGPT's "Browse" feature can visit a URL to summarize it, it cannot programmatically crawl a 500-page sitemap and return a structured CSV. However, ChatGPT is exceptional at writing scraping code. You can paste a snippet of a competitor's HTML into ChatGPT and ask: "Write a BeautifulSoup script in Python to extract all the text inside the .pricing-tier classes."
Final Thoughts on Automated Competitor Intel
The most successful growth teams treat competitor websites not as static brochures, but as living datasets.
By leveraging tools like Apify, Puppeteer, or Octoparse, you remove the guesswork from your competitive analysis. You stop wondering why a competitor is recommended by AI assistants and start seeing the exact data structures, citations, and content architectures driving their visibility. Extract those insights, map the gaps in your own strategy, and turn that missing data into your team's next high-performing published asset.